
Voice Cloning: speak for anyone you like

February 26, 2024
In a world where machines are starting to outshine human capabilities, the concept of voice cloning adds an exciting twist. Picture the possibilities: personal assistants with a human touch, characters in gaming that sound eerily authentic or book narrators with the voice of your favorite celebrity. It's not just about entertainment. Real-time voice cloning can also be applied to help people with medical conditions or disabilities that affect their ability to speak.

This article takes you on a journey into the mechanics of real-time voice cloning, unraveling its complexities in a straightforward manner. What makes this adventure even more interesting? Our target is none other than our SNGULAR colleague, chapter leader, and AI expert, Nerea Luis. You might be used to hearing Nerea talk about robotics and AI in shows like Orbita Laika and Cuerpos Especiales. Today, we will clone Nerea’s voice and you will hear her talking about something else: she will be reciting the beginning of The Lord of The Rings.
Voice cloning vs TTS – Coqui-ai
Voice cloning is the process in which one uses a computer to generate the speech of a real individual, creating a clone of their specific, unique voice using artificial intelligence (AI). Text-to-speech (TTS) systems, which can take written language and transform it into spoken communication, are not to be confused with voice cloning.
TTS systems are much more limited from the outputs they produce compared to voice cloning technology, which is really more of a custom process.
A very popular tool for voice cloning is coqui-ai TTS. Coqui is a startup that provides open-source speech tech. It is no longer in business but its github repository for voice cloning still has plenty to offer. Another interesting repository is All Talk TTS, which is based on the Coqui technology but offers an easy-to-use user interface. However, in this article we will use Coqui’s repository for our experiments.
How it works
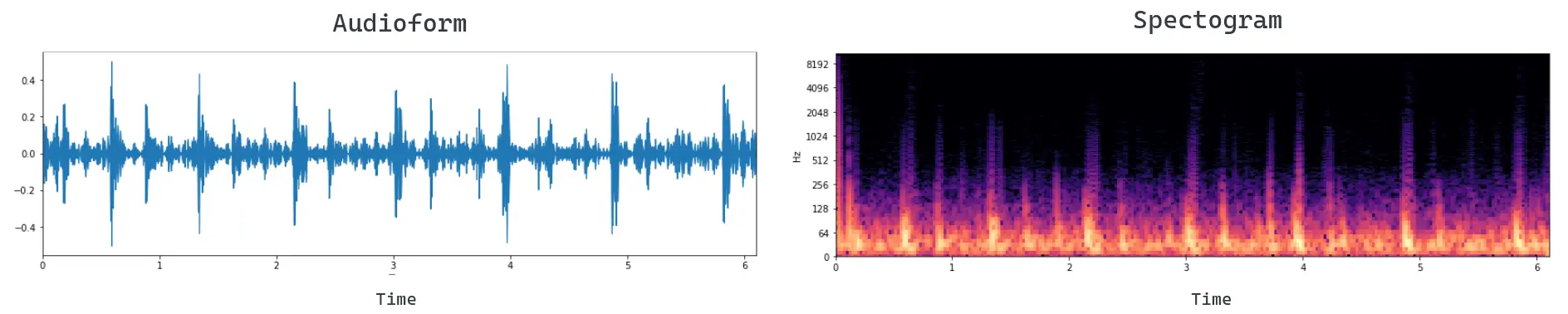 Figure 1: display of an audio signal in Audioform (left) and spectrogram (right).
Figure 1: display of an audio signal in Audioform (left) and spectrogram (right).
The typical voice cloning system consists of four main building blocks, four models that work together to enable you to clone the desired voice (see Figure 2).
- Text-to-Mel encoder: converts the text you want your speaker to read into a mel-spectrogram, which is a common way to represent speech. You can get more information on what mel spectrograms are in this Medium article.
- Vocoder or Voice Encoder: neural network that takes this mel spectrogram and converts it into a waveform. In other words, the Vocoder converts the spectrogram back into an audio signal (See Figure 1).
- Speaker encoder: neural network that takes in a short audio sample from the target speaker and encodes it into a fixed-length vector that represents the speaker’s unique voice characteristics. This vector is used to condition the vocoder during speech synthesis, allowing the model to generate speech that resembles the reference speaker.
- Real-time synthesizer: generates the audio file, which consists in the target speaker’s voice pronouncing the desired text.
In Figure 2 you can see a scheme showing the data flow through each mentioned building block inside a generic voice cloning system. Coqui offers multiple TTS model options. You can play around with them (and many others) in Coqui’s hugging space, and check their details in coqui’s documentation page.
For our experiments, we will use the XTTS v2 model, a voice generation model that lets you clone voices in different languages that yields very good results with just a 6-second sample audio clip from your reference speaker. Only showing the model one or few samples (without fine tuning it) you can get pretty realistic audios. If needed, it also allows you to fine tune it.
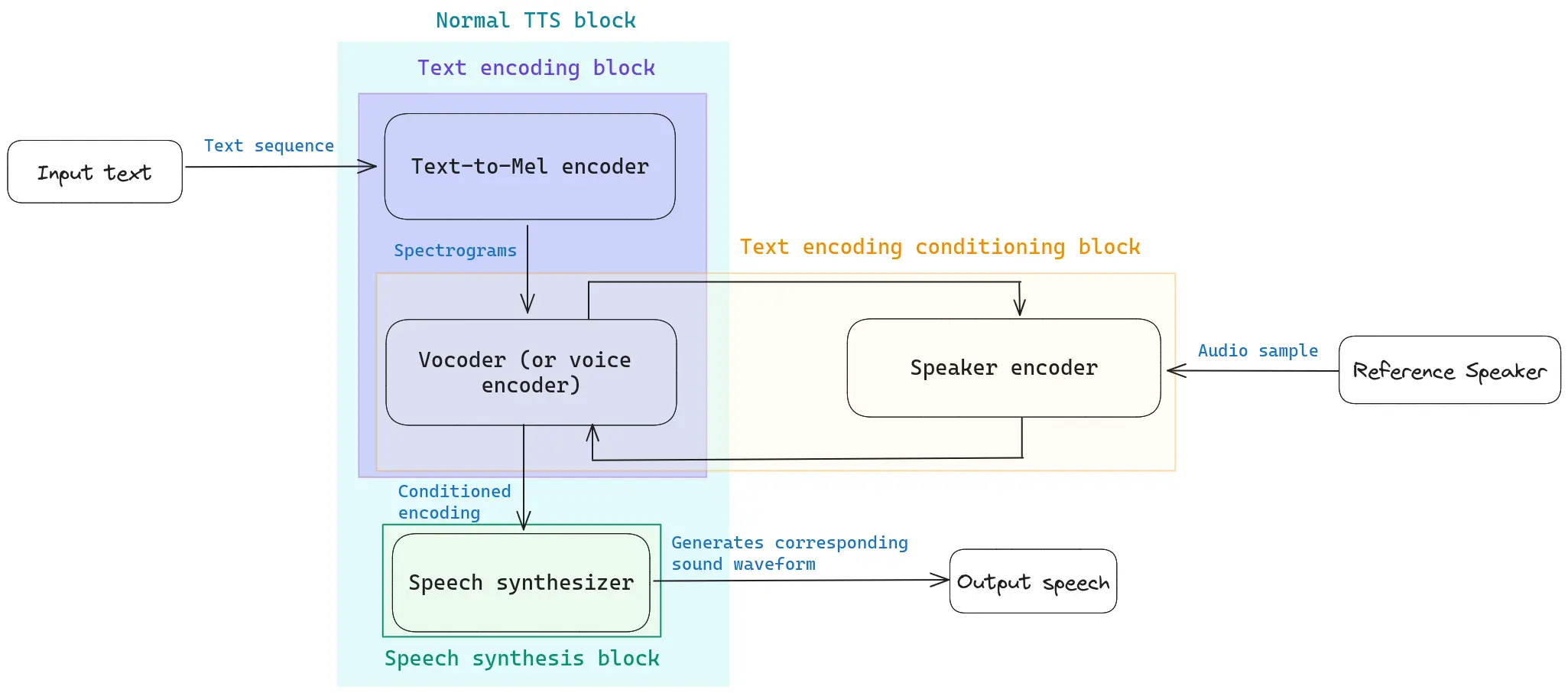 Figure 2: schematic summary of the data flow inside a generic voice cloning system.
Figure 2: schematic summary of the data flow inside a generic voice cloning system.
Step by step
For the implementation of coqui-ai TTS, you will need to install python >= 3.9, < 3.12. Here is a guide on how to install python, VSCode code editor and conda environment management tool.
Step 1: Environment configuration.
Go VSCode and open a new terminal. On that terminal:
conda create --name coquisTTS python=3.9
conda activate coquisTTS
pip install ipykernel
pip install TTS
Step 2: Record your sample audios and select the text.
In our case, we will use three 5 to 10-second audio files Nerea gladly sent us to use as samples of her voice. The speaker encoder will use them to condition the generated voice in Nerea’s style. We will also need to define what we want Nerea to say. I have been trying to read The Lord Of The Rings for ages, but I can never find the time. This is our chance: Nerea will read it out loud for us!
 Figure 3: a picture of Nerea sharing some laughs with the cast of The Lord Of The Rings.
Figure 3: a picture of Nerea sharing some laughs with the cast of The Lord Of The Rings.
Nerea is a native Spanish speaker, and the audio files she sent us are in spanish. XTTS\_v2 model allows for Cross-language voice cloning. This means that we can clone Nerea’s voice speaking in Spanish and make her read LOTR in perfect english. We will generate speech in both English and Spanish and compare results. Here are the selected texts:
Spanish:
*Cuando el señor Bilbo Bolsón de Bolsón Cerrado anunció que muy pronto celebraría su cumpleaños centésimo decimoprimero con una fiesta de especial magnificencia, hubo muchos comentarios y excitación en Hobbiton.
Bilbo era muy rico y muy peculiar y había sido el asombro de la Comarca durante sesenta años, desde su memorable desaparición e inesperado regreso. Las riquezas que había traído de aquellos viajes se habían convertido en leyenda local y era creencia común, contra todo lo que pudieran decir los viejos, que en la colina de Bolsón Cerrado había muchos túneles atiborrados de tesoros. Como si esto no fuera suficiente para darle fama, el prolongado vigor del señor Bolsón era la maravilla de la Comarca. El tiempo pasaba, pero parecía afectarlo muy poco.
English:
*When Mr. Bilbo Baggins of Bag End announced that he would shortly be celebrating his eleventy-first birthday with a party of special magnificence, there was much talk and excitement in Hobbiton.
Bilbo was very rich and very peculiar, and had been the wonder of the Shire for sixty years, ever since his remarkable disappearance and unexpected return. The riches he had brought back from his travels had now become a local legend, and it was popularly believed, whatever the old folk might say, that the Hill at Bag End was full of tunnels stuffed with treasure. And if that was not enough for fame, there was also his prolonged vigour to marvel at. Time wore on, but it seemed to have little effect on Mr. Baggins.
Step 3: Write the python code
Create a python notebook (e.g.: test.ipynb) and inside a cell, run:
from TTS.api import TTS
import torch
#Get device
device="cuda:0" if torch.cuda.is_available() else "cpu"
SAMPLE_AUDIOS = ["sample1.mp3", "sample2.mp3", "sample3.mp3", "sample4.mp3", "sample5.mp3"]
OUTPUT_PATH = "LOTR.wav"
TEXT = "Write here the text we want Nerea to read."
#Init TTS with the target model name
tts = TTS(model_name="tts_models/multilingual/multi-dataset/xtts_v2", progress_bar=False).to(device)
#Run TTS
tts.tts_to_file(TEXT,
speaker_wav=SAMPLE_AUDIOS,
language="en", # "es" if the text is in spanish
file_path=OUTPUT_PATH,
split_sentences=True
)
#Listen to the generated audio
import IPython
IPython.display.Audio(OUTPUT_PATH)
Results
Generated audio in spanish:
Generated audio in english:
In my opinion you can recognize Nerea speaking, but with a slight metallic tone, especially in the coss-language generated speech (the english audio). In addition, the audio might lack the characteristic naturality Nerea always speaks with. But I believe it is a bright starting point that could be improved by fine tuning the model.
Let Nerea finish this article sharing some of her ideas that her clone read outloud:
If you enjoyed this article, you can follow me on LinkedIN
Our latest news
Interested in learning more about how we are constantly adapting to the new digital frontier?
Tech Insight
January 31, 2025
Galen, SNGULAR’s comprehensive generative AI solution for hospital environments

Insight
December 10, 2024
Groundbreaking technologies today that will reshape the innovation landscape in 2025

Corporate news
December 4, 2024
Launched ConnectedWorks to Revolutionize Construction Site Management

Insight
December 4, 2024
A Journey of Innovation, Improvement and Magic