
Memory management in Swift

May 10, 2024
Introduction
In Swift, like in many other programming languages, memory management is an essential part to ensure optimal performance and prevent issues such as memory leaks or invalid memory accesses. This memory management primarily occurs in two areas: the Stack and the Heap. Be patient, you'll soon become familiar with these terms.
Let's outline some distinctions between Heap and Stack. Don't worry about memorizing everything; this table serves as a reference for any doubts about the features of these two crucial memory areas.
Stack and Heap, head to head
| Feature | Stack | Heap |
|---|---|---|
| Memory allocation | Static, performed during compilation | Dynamic, takes place at runtime |
| Access | Fast, due to automatic memory allocation and release | Slightly slower, involves more memory management through reference counters or ARCs |
| Used for storage | Data types by value: structures, enumerated... * | Data types by reference: classes, actors... * |
| Security | Each thread has its own memory stack, so no simultaneous accesses to "shared state" data can occur, which can produce the famous "race conditions". ** | All threads access the same Heap, so "race conditions" may occur, so the data must be protected against this eventuality. ** |
| Performance | Very high performance. *** | Lower performance due to various factors. *** |
* Does this mean that whenever you create a data type using Struct its objects will be stored in the Stack, no, unfortunately it is not that simple.
** Each execution thread has its own memory stack, whereas the heap is shared among all threads. Since multiple execution threads can allocate memory in the heap simultaneously, it needs to be protected using locks, semaphores, or other synchronization mechanisms. This results in a significant performance overhead.
*** Swift's memory management through the Stack, in a static way, is very efficient. The Stack works through a LIFO system, image 1. Swift can add the information it needs to the Stack, "Allocation", very quickly and clean it from the Stack just as fast, "Deallocation".
In Image 2 we can see another graphical representation of how Swift would add data to the Stack and how it would release it, when it is no longer needed, using this LIFO (Last in, First Out) system.
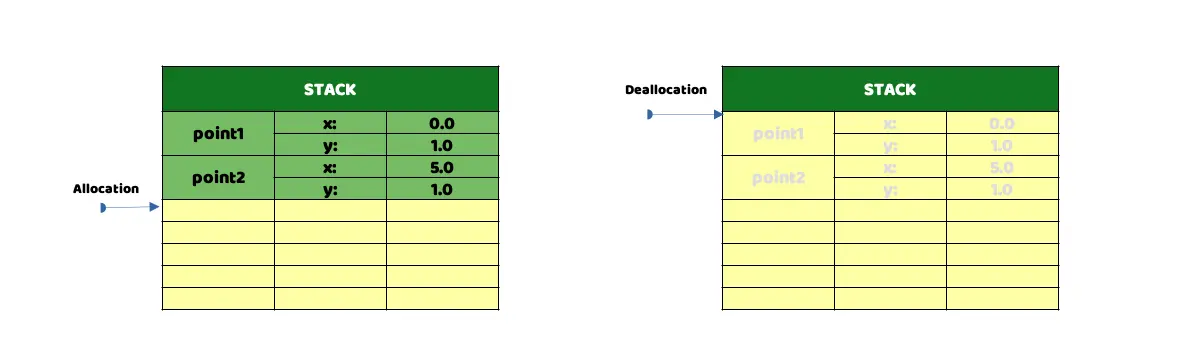 Representation of the Stack in memory, in one table the stored content is shown and in the second table the same after having been "released".
Representation of the Stack in memory, in one table the stored content is shown and in the second table the same after having been "released".
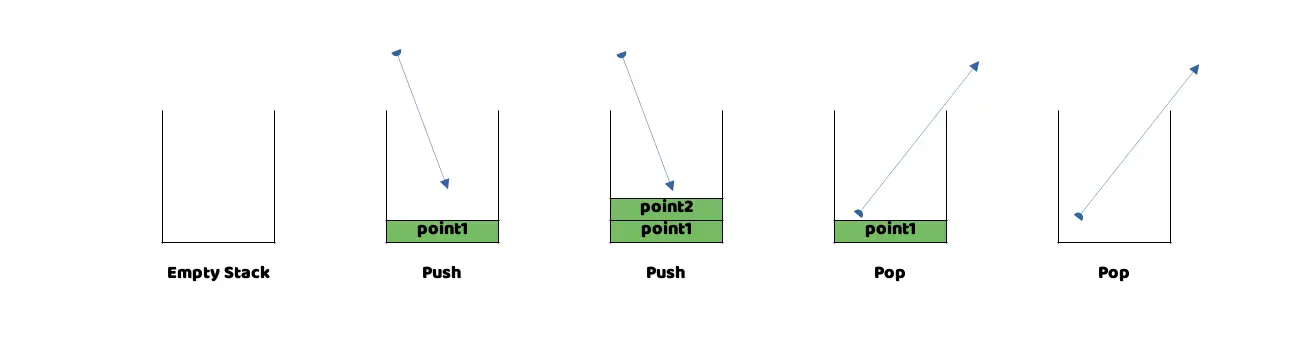 Graphical representation that shows the order in which the data is output and input in a Stack.
Graphical representation that shows the order in which the data is output and input in a Stack.
Meanwhile, dynamic allocation in the heap requires us to locate a memory space of the correct size and, when it's no longer needed, deallocate it properly. This incurs a much more complex, and thus less efficient, management process compared to storing items in the stack.
For optimal performance and efficiency in our abstractions, we must consider all the issues we've just discussed, along with others such as dynamic and static method dispatching, which we'll explore shortly.
Is there code or no code?
Let's see it with code, using the same examples that Apple put up at the WWDC 2016, "Understanding Swift Performance" conference.
 Displays source code with the definition of a structure.
Displays source code with the definition of a structure.
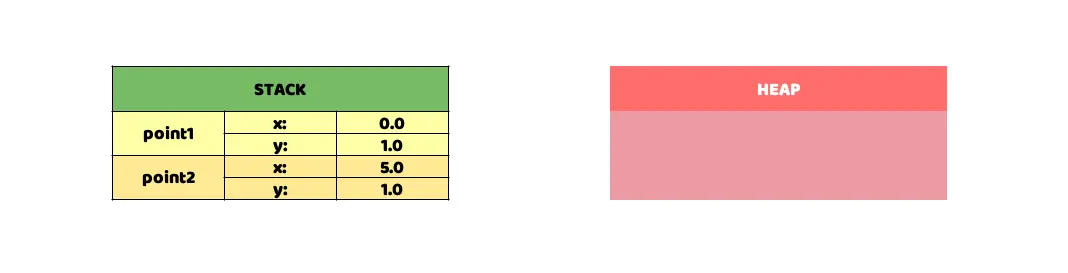 Displays a table with a visual representation, as an example, with the data stored in a grid.
Displays a table with a visual representation, as an example, with the data stored in a grid.
This simple example would not make use of the Heap, both structures would be stored in the corresponding Stack in memory. We have added a representation of how this Stack would be in memory, it is only a graphical representation, with no other pretension than to provide a visual aid to the explanation. How would it behave in memory if we were to use a class, let's see it with an example:
 Displays source code with the definition of a class.
Displays source code with the definition of a class.
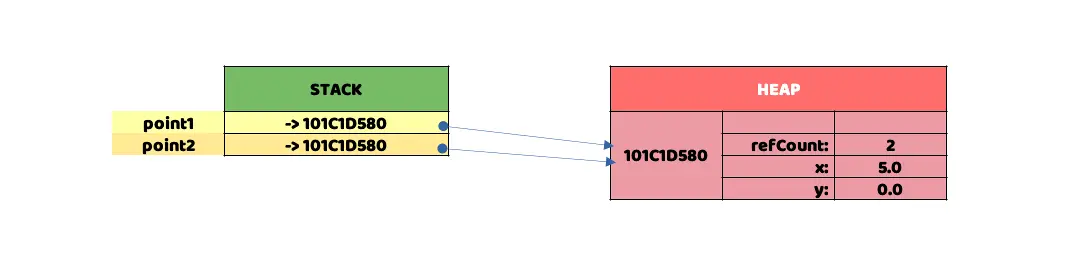 Shows a visual representation, as an example, with the data stored in two grids
Shows a visual representation, as an example, with the data stored in two grids
As illustrated in the memory representation, for this example, Swift must utilize the heap to store the data of the created object, incurring all the performance, security, and other costs we discussed in the previous section. Additionally, it's evident that Swift still needs to use the corresponding stack to store references to 101C1D580, both for the point1 and point2 objects.
101C1D580 is a sample memory reference, simulating a real one where the data would be stored. Many of you may wonder why there are four "memory spaces" when only two are needed to "store" the structure. Let's break it down: one of these spaces, which we'll call refCount, is used by ARC to store the number of "active references" pointing to that memory position. We'll discuss the last space later on.
When refCount reaches 0, it implies that it's no longer being "pointed to" by any object, so Swift proceeds to recycle it from memory. Have you ever been asked about "retain cycles" or "circular references" in an interview? We won't delve into that today, but as the saying goes: this is the general direction we're heading in...
Inefficient Structs and alternatives to inefficient Structs
Let's review the following implementation to learn, with an Apple example, of some traps we can fall into when implementing our functionalities, abstractions, etc:
 Displays a function that receives parameters of enumerated type and returns a uiimage.
Displays a function that receives parameters of enumerated type and returns a uiimage.
The function is responsible for generating the typical "balloons" seen in cartoons, comics, etc., to depict a conversation, complete with an arrow loop pointing towards the speaker. Our developer has cleverly used enums to define parameters such as color, orientation, and loop type, as these are finite and can be easily parameterized and managed. Additionally, they have created an array to store dictionaries, using a String key to retrieve the corresponding UIImage if it has been processed before.
Unfortunately you have not taken into account that such Strings will make use of the Heap and will incur reference counting, need for information protection, slower access, etc. And this is where we might be thinking, "But isn't the String in Swift implemented by a struct, didn't the Structures not have value passing, didn't you tell us that the Structures use the Stack?"
Well, it depends on the internal implementation of String. Similarly, as we'll explore later in this article, the implementation of our data types will determine whether they utilize the Stack or the Heap.
How can we optimize our code? Apple offers us the following alternative:
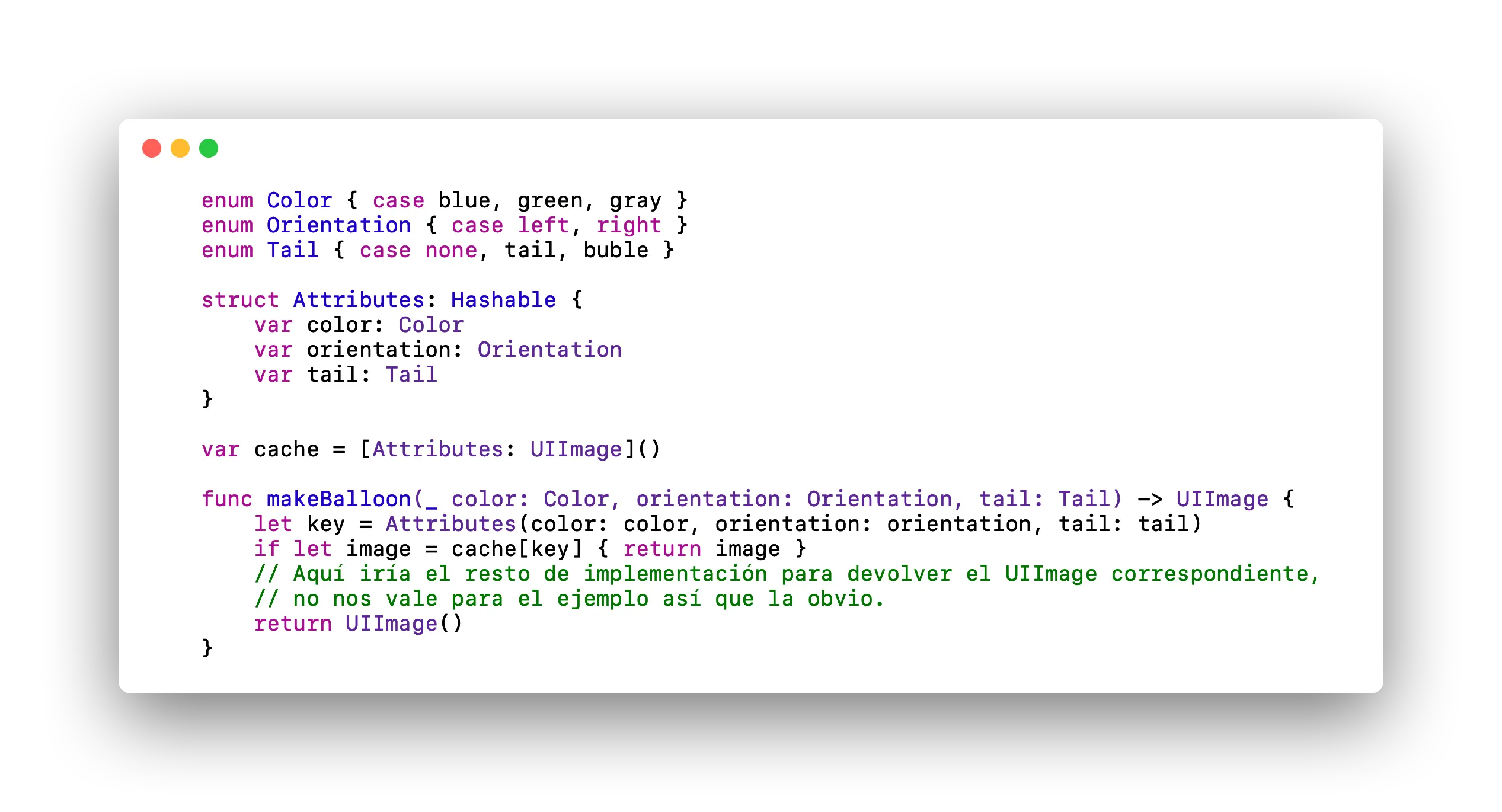 Shows the same function as the previous image changing the way it implements the function.
Shows the same function as the previous image changing the way it implements the function.
We can create a structure in which to "store" the values we need for the creation of our "balloon". We need it to implement the Hashable protocol so that it can act as a key in the dictionary. With this, we would also avoid using keys that may well have nothing to do with the content to be stored. But, is the change really noticeable, let's use our good friend XCTest to perform a few performance tests, in one of them we will use a structure to generate the key that would be used in the dictionary, in another we would use a class, also with the Hashable protocol implemented, and finally we would use a String, generating it the same way as in the initial example:
 Displays the code of the executed performance tests.
Displays the code of the executed performance tests.
The first test, using Strings, took 1.7 seconds on average to run (it runs 10 times and shows the average of all executions). The second, with classes, 0.198 seconds and the third, using structures, 0.160 seconds.
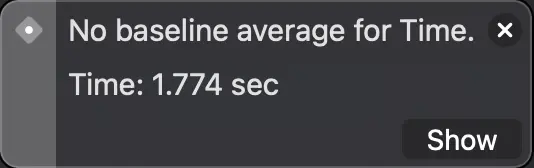
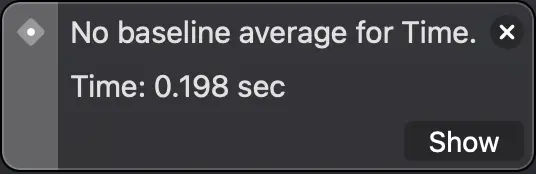
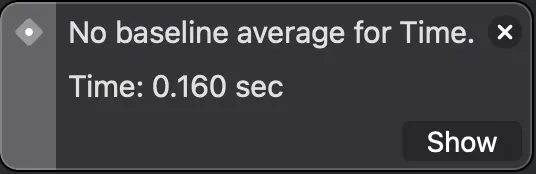 Shows the time it took for the tests to run.
Shows the time it took for the tests to run.
With these results we can appreciate the high cost of allocating strings in memory. On the other hand, the difference between using structures and classes may not seem very big, approximately 19%, but we must take into account that this is only the cost of its allocation, we should also add the subsequent cost of using the class in relation to the structure...
Structures more inefficient than classes
Does this imply that a structure will always be more efficient than a class? Unfortunately, no. Once again, it depends on the implementation of the structure itself. In the example implementation for the Point structure, we observed that no use was made of the Heap, there was no reference counting, and everything was stored in the Stack. However, for more complex structures, let's examine the following example:
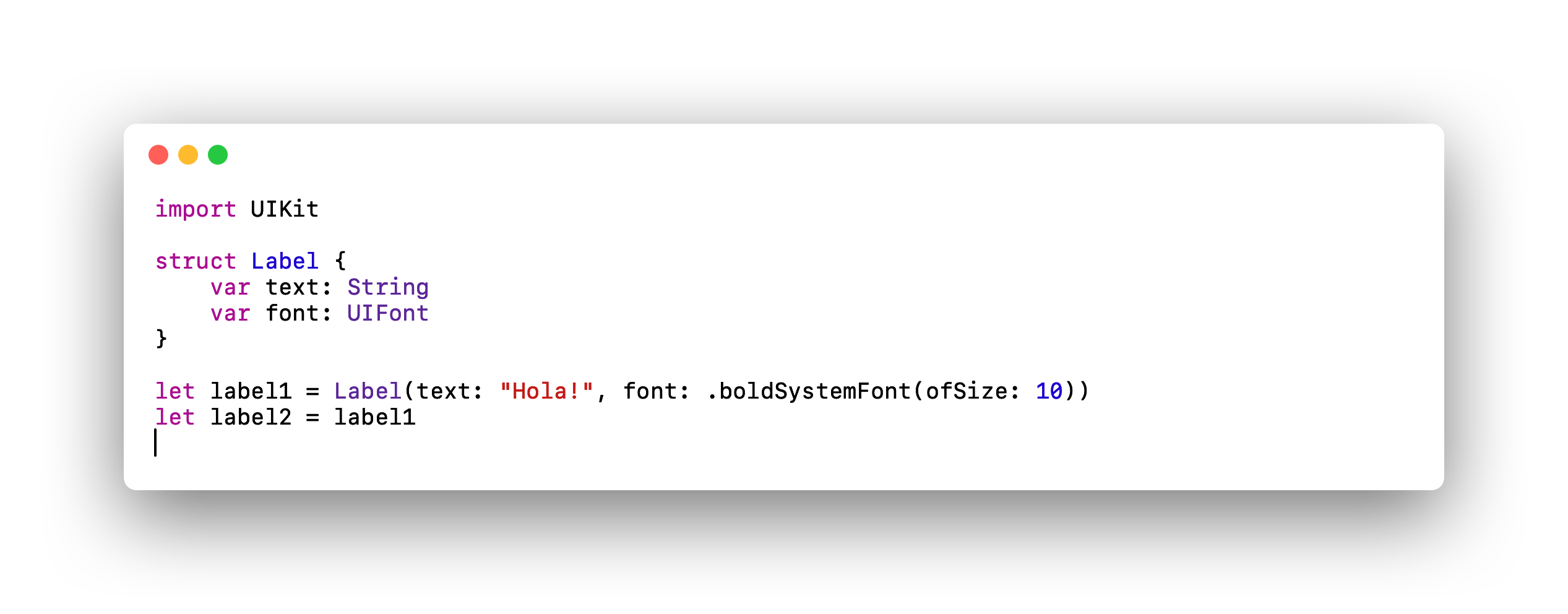 Displays the code of an inefficient structure.
Displays the code of an inefficient structure.
We find ourselves with a structure that has two properties, one of type String and another of type UIFont. As we saw in the previous section, String makes use of the Heap even being implemented as Struct and UIFont is a class so it would also make use of it.
What does this mean? The instance "label1" would have two references, one for the String and another for the UIFont. When making a copy with "let label2 = label1", two more references would be added, one for each of the properties.
At the 2016 developer conference, Apple commented that managing the count of such references was not trivial because it occurred so frequently.
In this particular case, the use of structures would result in an overhead of twice as many references compared to what it would have been if it were a class.
Let's optimize another example
Let's review another example, in this case an abstraction for an attachment that could be used by an e-mail management program.
 Code image of an inefficient structure.
Code image of an inefficient structure.
If we take into account everything we read in the previous section, this structure would be incurring a higher reference count. Shall we see how to improve it?
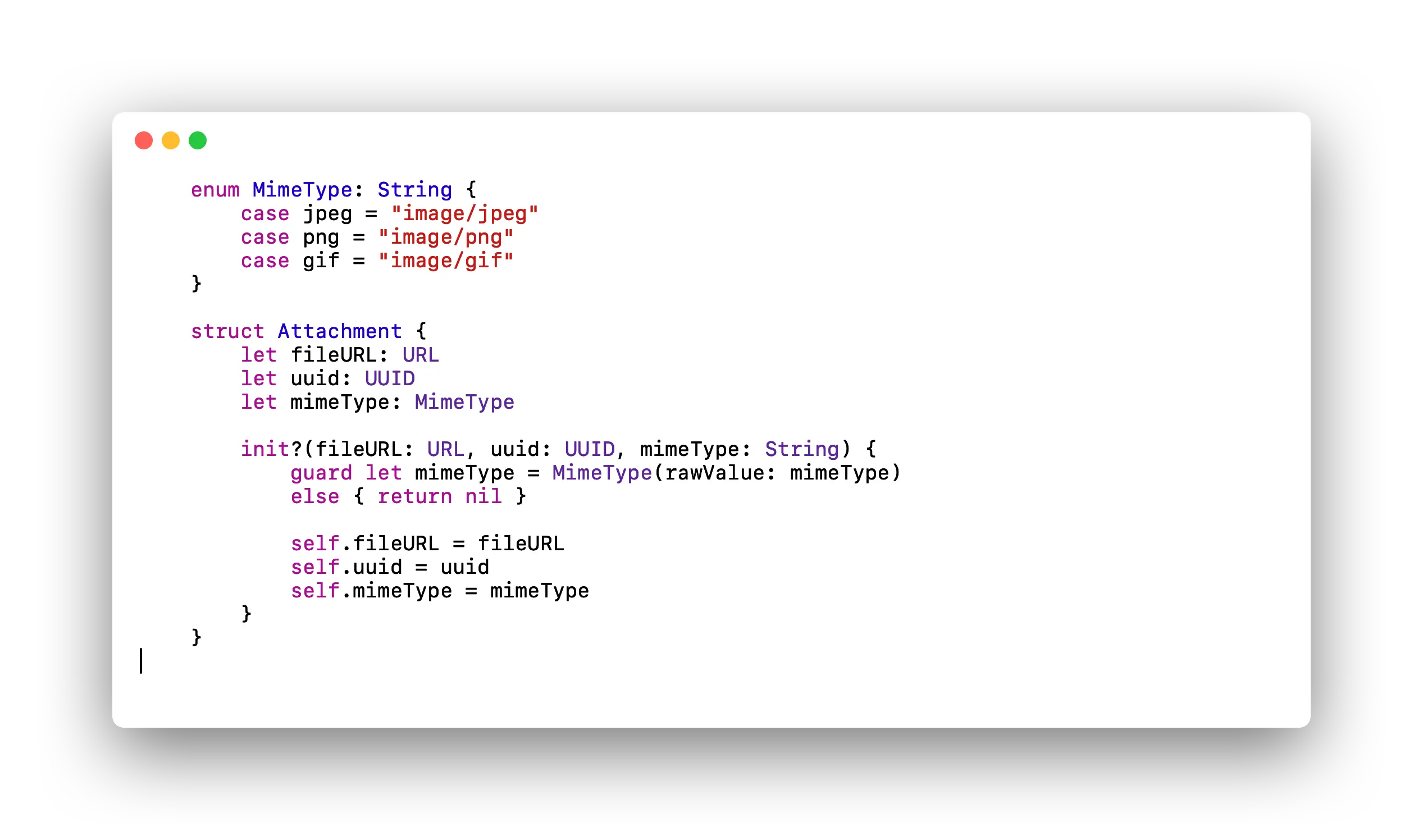 Image showing the above code in a more optimized form.
Image showing the above code in a more optimized form.
First, we can use UUIDs, available since iOS 6.0, to obtain a 128-bit randomly generated identifier. Using UUID helps ensure that any String cannot be used as a unique identifier, which may not be appropriate for its intended purpose. UUID is a value-type data type that directly stores those 128 bits in the structure, within its corresponding Stack, without the need for reference counting overhead.
For the attachment type, we can utilize enumerated types, which are powerful in Swift. By doing so, we transition from having a property with reference counting and Heap usage to another property with storage directly in the structure within the corresponding Stack.
However, we still need to manage a reference for the URL type property, even though it is implemented as a Struct. This is because it would be assigned directly in the Heap. It's a similar case to String; although both are structures, their internal implementation necessitates the use of references.
Method dispatch (static and dynamic)
Do you remember that when we talked about memory spaces we referred to two extra spaces in the case of using classes, if you go back in this same article you will find that one of those "extra spaces", Swift, was dedicated to save the reference count. Well, let's see what the remaining one is dedicated to.
When we use a class method, at runtime, Swift needs to know which implementation of the method is correct. If it is able to determine this at compile time, Swift will be able to optimize our code more efficiently. This is what we call static dispatch, which can be translated as static dispatch, static dispatch, etc.
This "dispatch" system stands in contrast to the "dynamic dispatch" system. In the dynamic dispatch system, Swift cannot determine the appropriate implementation at compile time. Instead, it must search for it at runtime and execute it. While this search itself does not necessarily result in a significant loss of performance compared to static dispatch, we do forfeit all the optimizations that Swift could have applied to our code during compile time.
Now, let's return to the code to see an example. We'll revisit the Point structure and add a method to draw the point. We won't provide any implementation because it's not relevant for this case:
 Shows an image with code of a function using a structure.
Shows an image with code of a function using a structure.
Nothing complex in the code shown. But in this example there is a part of the code that is a candidate to be optimized, automatically, by the compiler using a technique that, in Swift, is called "inlining".
 Same image with changes occurring after "inlining".
Same image with changes occurring after "inlining".
This is a very simple example in which the call to the drawAPoint function has been replaced, at compile time, by the direct call to the draw method of the point instance. Let's see another simple example:
 Displays an image with code of a function and its use.
Displays an image with code of a function and its use.
In case the compiler decided to use "inlining" with this code the finally compiled code could be similar to this other example:
 Simulation of how the code might look after inlining.
Simulation of how the code might look after inlining.
Why 'let twoPlusOne = 3', because in this example the compiler would already have all the necessary information to calculate the result, so we would add an additional optimization to the "inlining" optimization by having the result of the equation at compile time, without the need to calculate it at run time.
As this is a single example, it may not be given the proper importance, when it really has it, since these optimizations could affect data structures that were calculating some of these operations at runtime a very high number of times.
To summarize: "inlining" refers to the process in which the compiler replaces a function or method with its contents directly where it is used. This is done to improve program performance by minimizing function calls and eliminating the need to save and restore previous states in shared state instances, etc.
Well, let's continue reviewing the code, we are getting closer to complete the enigma of the spaces reserved for classes.
 Displays the code of a class and two subclasses.
Displays the code of a class and two subclasses.
Here we find a Drawable class. This class has a draw() function. If you are getting ahead of yourself and in your head there is already a little voice saying "that shouldn't be a class, it should be implemented as a protocol...": ok, but buy me the example, or, better yet, buy it from Apple, it's theirs.
There are also two child classes of Drawable, Point and Line, both of which overload the draw() function of their parent class and implement their own functionality. If we were to work with an array of objects of type Drawable and we were to add different instances of both points and lines, we would encounter a problem. When going through the array and using the draw() function of each object of type Drawable, which implementation should be used?
Here the remaining space comes into play: a pointer to the type information of the corresponding class. Let's take a look at the following representation:
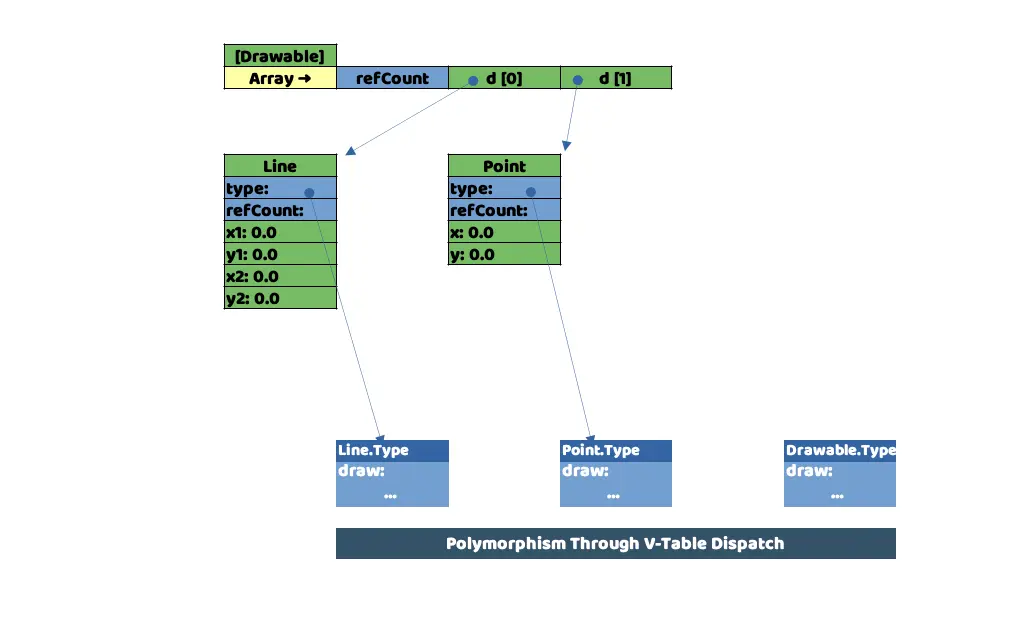 Representation of how the above code would look like in memory.
Representation of how the above code would look like in memory.
What can we learn from this representation of memory, for example, that the arrays also have their own space reserved for counting references, which would indicate that it is also stored in the Heap of the memory and that each of the Stacks that use it will be storing a memory reference to it.
Line and Point, even being child classes of Drawable, have different sizes since Line must store more information than Point, why is this not a problem for the array, because in each of the reserved spaces (d[0] and d[1]) what is stored is the reference to the memory address of each of the objects.
And, finally, we get to complete the missing data. In the space reserved by each instance of the class what we store is the, previously mentioned, pointer to the memory address where Swift has stored the implementation of the method to be executed for each type of data.
The lower part of the image can be called "method table", or "virtual method table". As a side note, this behavior is common to other object-oriented programming languages such as Java or C++.
Once again, we might think that it shouldn't make a significant difference. However, in many cases, not knowing which method to "serve" statically could prevent a series of optimizations for our code. For instance, in a chain of methods, encountering this level of indirection would prevent the compiler from optimizing subsequent calls, even if the remaining "dispatches" could be calculated at compile time.
Do you now understand why it's crucial to mark all classes that won't have subclasses inheriting from them as "final"? It wasn't just a quirk of the senior developer. The compiler recognizes this and performs static dispatch of methods for instances of such classes.
Conclusion
In summary, we have explored in depth the use of Heap and Stack memory in Swift, understanding the fundamental differences between the two areas and how they affect the performance and security of our applications.
It's important to emphasize that the aim here isn't to vilify the use of classes in Swift, but rather to comprehend when and how to use them effectively. Classes are a potent tool provided by Swift, yet we must acknowledge their implications in terms of dynamic memory allocation, reference management, and performance.
Hence, the crux lies in utilizing classes when their inheritance, polymorphism, and shared reference capabilities are truly needed. For scenarios where these features are unnecessary, such as with simple data types or structures acting as values, opting for structs is preferable. Structs offer more efficient performance by leveraging the memory stack and avoiding overhead in reference management.
In conclusion, the decision between classes and structures in Swift should be grounded in a clear understanding of the design requirements and performance characteristics of each option. It's imperative to strive for code efficiency while maintaining clarity, but delving into this topic warrants another article altogether.
Our latest news
Interested in learning more about how we are constantly adapting to the new digital frontier?

Tech Insight
January 13, 2025
How to bring your application closer to everyone

Tech Insight
December 19, 2024
Contract Testing with Pact - The final cheetsheet

Insight
December 18, 2024
Agility, Complexity and Empirical Method

Tech Insight
December 17, 2024
Google’s new quantum processor is here, but what does it really mean?